Hi all – given the range of discussions we have been having about AI/LLMs – I think you will find the following article very interesting. It’s quite a long read but reveals some
important differences in the models. Also introduces some that I’ve not heard of.
Will we be taken over by bots I wonder??
Liz
From: Elina Halonen from Thinking About Behavior <thinkingaboutbehavior+artificial-thought@substack.com>
Sent: 24 March 2025 11:00
To: liz@yada.org.uk
Subject: How LLMs think differently
What a historical currency question revealed about how AI models interpret ambiguity, frame problems, and shape our understanding of the past.
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
͏
How
LLMs think differently
What a historical currency question revealed about how AI models interpret ambiguity, frame problems, and shape our understanding of the past.
This is the first post in a new section of the Substack,
Artificial Thought - you can opt out of these emails in
your account settings.
AI is often framed as a tool for finding answers—but what happens when different models give entirely different answers to the same question? That’s exactly what happened when I asked six large
language models a seemingly straightforward historical query: how much would a sum of money from 1770 North Carolina be worth today?
Instead of one answer, I got six wildly different responses—calculations, caveats, historical detours, ethical framing, or none at all. Some treated it like a maths problem, plugging in inflation
multipliers. Others approached it like a history essay, grounding it in social context. Some introduced ethical considerations early; others ignored them completely.
This raised a bigger question: how do AI models approach problem-solving differently—and what does that mean for how we use them?
This wasn’t just a curiosity—it became a window into how different models frame problems, interpret ambiguity, and prioritise information. Not how accurate they are, but how they think.
How this experiment came about
This started with casual curiosity. I was watching a historical drama when a character mentioned a financial gift—some pounds, given to relatives, in 1770 North Carolina. The lawyer in the scene
reacted as though the amounts were significant. I couldn’t tell if they were.
I tried Googling it, but quickly ran into a wall. Colonial currency wasn’t standardised—different colonies used different systems, and values weren’t directly comparable. Inflation calculators alone
weren’t enough. Understanding the worth of the gift required historical and economic context: wages, land prices, and the political economy of enslaved labour.
That complexity made it a perfect test case for AI. Would a model treat it like a simple conversion? Would it bring in historical nuance? Would it consider the ethical backdrop of inherited wealth
in the 18th-century American South?
So I decided to ask and to see where each model would take me.
How I ran the experiment
This didn’t start as a planned experiment. I asked ChatGPT and DeepSeek the same historical question out of curiosity—what would sums of money from 1770 North Carolina be worth today? I ran a short
dialogue with each, asking a series of increasingly contextualised questions about historical value, social meaning, and economic framing.
While testing them, one response in particular caught me off guard. DeepSeek spontaneously introduced ethical framing after just the third question—highlighting how gifts of land or money in that
context were deeply entangled with the plantation economy, class structure, and the exploitation of enslaved people. At that point, ChatGPT had said nothing on the subject, and most of the other models never brought it up at all. That contrast made me wonder:
how would other models handle this?
So I expanded: I ran the same series of prompts with four more LLMs—Claude, Gemini, Mistral, and Qwen—keeping the questions consistent and allowing each interaction to unfold naturally, just as it
had the first time.
You can see the full conversations on this
Miro board.
What I asked
The question evolved over the course of the conversation. Here's the full sequence of prompts I used with each model:
Comparing how models approached the question
Each model answered the same questions but in very different ways. Some treated it like a calculation, others like a case study. Some structured their reasoning from the outset; others unfolded it
in loosely connected paragraphs. What these responses revealed wasn’t just a difference in accuracy—it was a difference in how the models framed the task in the first place.
Here’s a snapshot of how each model approached the question, and what that style meant for the user experience:
What these responses reveal is not just variation in training or capabilities, but variation in priorities: what to answer first, how much context to add, whether to speak with certainty or caution.
Those decisions shaped how the responses felt and turned one historical question into six very different conversations
Summary of response content and approach
If you’re interested in a deeper breakdown of how each model handled these issues, there are detailed comparison tables at the end of this article. In the rest of the article the LLMs will be
referred to without their model numbers.
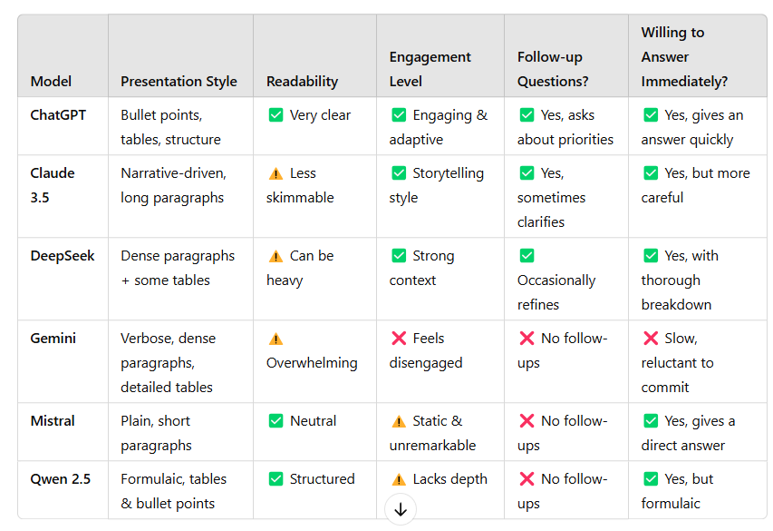
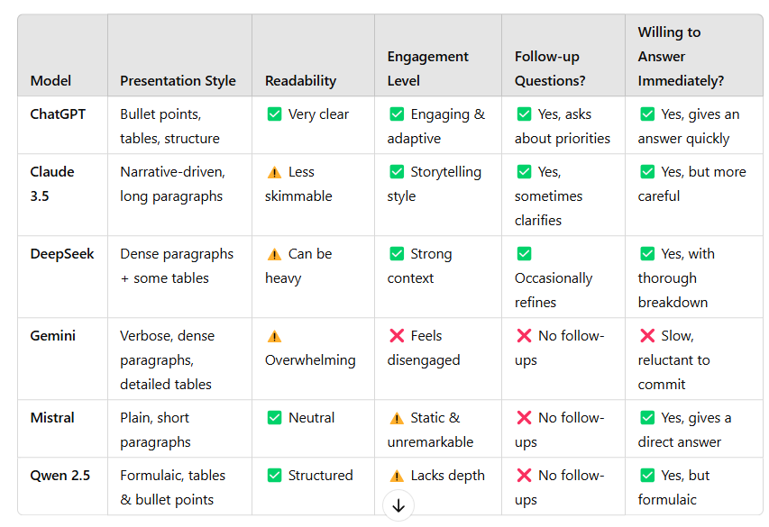
How AI models communicate and respond to users
Comparing AI models isn’t just about what they say—it’s about how they say it. Some reply in bullet points, others in essays. Some aim to
solve the problem, and others focus on
explaining why the problem is complicated. These differences aren’t just stylistic flourishes because they shape how you interpret
the answer, how likely you are to ask a follow-up, and whether you feel like you’re in a conversation or reading from a prepared script.
Presentation style: how do they structure information?
Some models get to the point, others take the scenic route. The format they choose doesn’t just affect readability—it shapes how you make sense of the information and what you do next:
Takeaway: Structure helps when you’re figuring something out, storytelling helps when you’re reflecting. Whether
you want one, the other, or both depends on what kind of task you're trying to solve.
Interaction style: do they adapt, refine, or follow up?
Some models behave like thinking partners, others feel more like calculators with a narrative setting:
Takeaway: Responsiveness changes the experience— it’s the difference between a dialogue and a data dump.
How LLMs communicated and responded
The structure and tone of each response shaped how easy it was to follow the argument, how much trust it inspired, and how likely I was to keep going. Often, what made an answer
feel useful had less to do with content and more to do with delivery.
Who would you want as a colleague or customer service agent?
LLMs vary not just in what they say, but in how they say it. Some speak in bullet points, others in paragraphs; some answer immediately, others warm up with three paragraphs of context. They also
differ in tone, pacing, and problem-solving style.
To make these styles easier to compare, I’ve reimagined them in human terms. If each model were a colleague, what kind of teammate would they be? If they staffed your help desk, who would guide you
patiently, and who would hand you a number and move on?
It’s a lighthearted frame, but it reflects something real: communication style, responsiveness, confidence, and depth. These traits shape the user experience more than most prompt engineering tips
ever will—and knowing which persona fits your task makes it easier to choose the right model for the moment.
LLMs as customer service reps
For many users—especially early on—interactions with a language model feel transactional. You ask a question. You get an answer. It’s less like working with a tool and more like talking to a help
desk.
In that setting, tone and structure matter more than you might expect. One model gives you a number and moves on. Another delivers five paragraphs and an analogy. Some feel scripted. Others feel
conversational. These differences may seem stylistic—but they shape whether you feel helped, dismissed, or confused.
If Gemini were your first touchpoint, you might reasonably conclude that LLMs are vague and overly cautious. If Qwen was your entry point, you might think they’re fast but rigid. Either way, that
first encounter sets the tone for how you think LLMs work—and what you think they’re good for. That’s why communication style isn’t just a design choice: it shapes expectations, trust, and how likely you are to try again.
Which model would you want as a colleague?
LLMs vary not just in what they say, but in how they say it. Some speak in bullet points, others in paragraphs. Some answer immediately. Others warm up with three paragraphs of context. Once you’ve
used a few, you start noticing patterns—and they begin to feel less like tools, and more like familiar work personalities.
They differ in tone, pacing, and problem-solving style. One model gives you a structured plan before you’ve finished asking the question, another offers a series of disclaimers before gently sidestepping
your request. The interaction starts to feel less like querying a machine and more like navigating workplace dynamics.
So to make those styles easier to compare, I reimagined each model in human terms. If they were colleagues, who would you ask for help? Who would give you clarity—and who would hand you a spreadsheet
and disappear?
Summary of LLMs as colleagues or customer service reps (based on this experiment)
It’s tongue-in-cheek, but not wrong. Style, tone, and responsiveness shape your experience far more than any clever prompt ever will. Once you know which model works like a spreadsheet and which
one talks like a seminar, picking the right one gets a lot easier.
What this experiment revealed
This wasn’t about scoring models or declaring winners. It was a way to observe how different language models handle ambiguity—how they interpret context, weigh trade-offs, and decide what kind of
answer to give.
What emerged wasn’t a single standard of helpfulness, but a range of styles and priorities. Some models focused on structured precision, others leaned into storytelling, and a few introduced ethical
framing without being prompted. None of them were interchangeable. Each brought its own assumptions, its own communication style, and its own blind spots.
Prompting, too, shaped the experience but not because the prompts changed. Each model interpreted the same questions differently, revealing distinct framing choices in how they structured, qualified,
or contextualised their answers.
Using these models felt less like consulting a tool and more like choosing a collaborator. Some structured my thinking for me while others required me to do the structuring myself—that’s what makes
understanding these differences useful. Once you start noticing how models present information, how they engage (or don’t), and how they respond to uncertainty, you’re in a better position to choose intentionally—not because one is universally better, but
because different tasks require different minds.
What began as idle curiosity—a throwaway question from a historical drama—ended up showing something more interesting: not just how language models answer questions, but how they
frame them, interpret them, and reshape them as part of the exchange.
Appendix
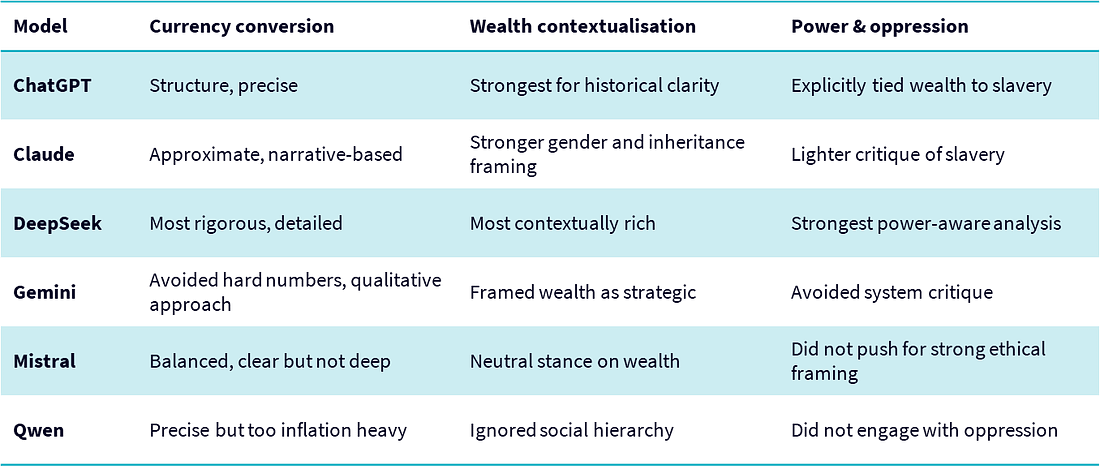
Currency conversion accuracy: precision versus uncertainty
Different models took different approaches to historical money conversion. DeepSeek and ChatGPT provided the most rigorous, well-researched estimates, using inflation and purchasing power calculations.
Qwen followed a similar approach but inflated the values more aggressively. Claude relied on rough approximations, while Gemini avoided specific numbers altogether, instead focusing on historical variability.
This highlights a key distinction: some models aim for precision, while others prioritise context. For users needing a direct answer, DeepSeek and ChatGPT are the most reliable. However, if the goal
is to understand economic uncertainty over time, Gemini’s qualitative approach provides useful perspective.
Contextualisation of wealth: wealth as power, not just money
Wealth in 1770 North Carolina wasn’t just about money—it was about land, social class, and power. DeepSeek and ChatGPT gave the most structured breakdowns, linking sums of money to social hierarchy,
land ownership, and purchasing power. Claude excelled in explaining gender and inheritance but gave less focus to enslaved labor. Gemini framed wealth as strategic influence rather than power or oppression, while Qwen focused purely on economics, largely ignoring
social hierarchy.
These differences matter depending on the user’s needs. For a thorough historical breakdown, DeepSeek and ChatGPT stand out. For understanding how wealth shaped gender and family strategy, Claude
is stronger. Gemini offers a detached, strategic lens, but lacks deeper critique.
Power and oppression framing: wealth built on exploitation
Not all models engaged with the reality that wealth in colonial North Carolina was built on oppression. DeepSeek and ChatGPT were the most explicit in tying wealth to slavery and class power, warning
against historical revisionism. Claude acknowledged gendered power structures but did not deeply critique slavery. Gemini and Qwen both treated wealth as a neutral economic force, largely avoiding systemic oppression.
This reveals an important limitation—not all models critically engage with history. Users seeking a nuanced, power-aware analysis should rely on DeepSeek or ChatGPT, while Claude is useful for gender-focused
narratives. Gemini and Qwen, while informative in other ways, largely sidestep ethical critiques.
Ethical considerations in storytelling: historical accuracy versus neutrality
When it comes to responsible storytelling, models varied in how they handled ethical framing. DeepSeek and ChatGPT were the only ones to explicitly warn against romanticising wealth and erasing the
role of slavery. Claude framed wealth in terms of gender and power but did not strongly critique it. Gemini remained neutral, treating economic history as strategy rather than morality. Qwen ignored ethical framing entirely, focusing purely on financial analysis.
This highlights a major gap in some LLMs’ ability to handle ethical storytelling. For users looking to explore history with moral awareness, DeepSeek and ChatGPT are the best choices. Claude provides
useful insights into power and gender but lacks ethical critique, while Gemini and Qwen avoid moral framing altogether.
Best Answer for Accuracy
Ethical sensitivity varies widely
AI’s engagement with historical ethics differed significantly across models:
This suggests that users looking for
ethically nuanced responses should lean toward certain models while avoiding others that downplay or ignore such considerations.
Earlier versions of analysis
Thinking About Behavior is free today. But if you enjoyed this post, you can tell Thinking About Behavior
that their writing is valuable by pledging a future subscription. You won't be charged unless they enable payments.
© 2025 Elina Halonen
|